
Durable RAG with Temporal and Chainlit
Large Language Models (LLMs) are becoming increasingly common in Enterprises to surface information from large corpus of corporate data, and so are the expectations placed on them. It's common knowledge that LLMs can hallucinate when the context is too broad, or they're asked questions outside of their knowledgebase.
To solve this problem, advanced Retrieval Augmented Generation (RAG) techniques can be used to ensure their responses are grounded in the data (context) and they don't hallucinate. The foundation of any RAG system is its data. Enterprises can have data in various shapes and forms with diverse file types such as PDFs, markdown, docx, csv, Json etc., The RAG system will ingest data by chunking it into smaller pieces and converting them into vector embeddings and store in vector database.
Depending on the complexity of the system, libraries like spaCy can be used for Token, Sentence, and Semantic Chunking. Additionally, frameworks like LangChain can be used for adding chunking methods such as from Recursive to Code and Markdown chunkers. By leveraging the power of Vector Databases to perform Semantic Search, and applying various strategies for Chunking Data, Re-Ranking, Query Transformation etc., we can build a resilient RAG system that can ensure the responses generated by LLM are relevant to the users' questions and grounded in the context given to it.
Today, when we talk about AI-powered assistants, it's expected that such an assistant can search the web, find information in uploaded documents, or even generate a SQL query to retrieve results from a database, and use other tools/frameworks to create business intelligence dashboards with charts and graphs based on the retrieved data.
A single user request can trigger multiple actions across different systems—such as HTTP calls, SQL queries, or web scraping, to name a few. The outcomes from these actions might then be used to invoke another set of tools. The number of tools and their complexity is increasing daily. As a result, the simple request-response model is evolving into a multi-layered, multi-system service architecture, where even a minor failure in one system can disrupt the entire process.
A common approach is to add retry mechanism or circuit breakers to every call the system makes, but as a result, the code ends up being too complicated and filled up with different hacks implemented differently for different parts of the system: complex try-catch blocks, complicated retry policies logic and so on.
Temporal Durable Execution Framework can help solve this problem by bringing durability and resiliency into multi-step RAG workflows. With Temporal, developers can focus on writing the code which matters - business logic, instead of spending hours trying to troubleshoot and bugfix a transient error in a retry policy logic. With Temporal, everything is a workflow, and every step in the workflow can be defined as an action, like calling an HTTP API or saving data to the database.
Temporal ensures all steps in the workflow are completed and any transient failures are addressed by applying re-try, circuit breaker etc., A more detailed introduction to Temporal can be found here.
In theory, Temporal is perfect fit for our task - making sure that all requests are completed no matter what, all information is gathered properly, and a response is successfully returned to a user. If any process fails during the execution, Temporal rehydrates the entire process on a different server and continues the flow of execution from the exact point where it crashed. It can do this because all the workflows in Temporal are stateful. It maintains the full state of the workflows in its internal database, so it has complete visibility into what happened.
To see it in practice, our engineers at TechFabric created a simple proof-of-concept application to prove that such an approach makes sense and that it really makes it easier to develop and debug complex RAG applications.
Let's walk through the application to see how it is architected.
Chainlit
To make things easier, we took Chainlit as a starter kit for Conversational UI. Chainlit provides everything we need to get started - nice and clean UI and a python server app where we can write the logic and calls to LLM!
All we need to do is to define two methods: @cl.on_chat_start and @cl.on_message.
Temporal: Everything is a workflow
We talked about the approach for designing business logic via workflows in our Airlines proof of concept. So here we jump directly into the code.
The full code repository is on github, so here we will focus only on important parts, imports and non-relevant code will be omitted.
In Temporal, everything is a workflow and chatbot conversations are no different. When a user opens a page and starts a new thread, @cl.on_chat_start is called. That's a method where we start a workflow.
1@cl.on_chat_start
2async def start_chat():
3 client = await get_temporal_client()
4
5 cl.user_session.set("id", str(uuid.uuid4()))
6
7 # create a workflow id that will unique for user session.
8 workflow_id = get_workflow_id(cl.user_session)
9
10 handle = client.get_workflow_handle(
11 workflow_id=workflow_id,
12 )
13
14 start_new_workflow: bool = False
15 try:
16 # there are multiple ways of starting a workflow only if it's not already started. This is
17 # a first option. Another option will be to use SignalWithStart method.
18 workflow_status = await handle.describe()
19
20 if workflow_status.status != 1:
21 start_new_workflow = True
22 except Exception as e: #.describe() throws an exception if workflow does not exists
23 start_new_workflow = True
24
25 if start_new_workflow:
26 handle = await client.start_workflow(
27 ConversationThreadWorkflow.run,
28 ConversationThreadParams(
29 remote_ip_address="40.40.40.40" # random ip, TODO: add code to get client ip address
30 ),
31 id=workflow_id,
32 task_queue="conversation-workflow-task-queue",
33 )
34
35 thread_id = None
36
37 while(not thread_id):
38 thread_id = await handle.query(ConversationThreadWorkflow.get_thread_id)
39 await asyncio.sleep(1) # we are not inside a workflow so it's okay to make
40 # few calls to a workflow waiting for a thread id.
41 # Use such technique with care since it can cause performance problems
42
43 # Store thread ID in user session for later use
44 cl.user_session.set("thread_id", thread_id)
45
46Now, every time we open a Chainlit page it will generate a new user session and start a new workflow (new conversation thread, speaking in OpenAI API terminology). Workflow implementation does not matter at this point, all we need to understand is that one conversation thread = one conversation workflow. Such workflow can be started with arguments, in this example we used an IP address to show how one could use geocoding and weather API for chatbot to be able to answer questions like "what is the weather like today?"
Sending a message
Sending a message is as easy as sending a signal to a workflow passing user's prompt as an argument.
1@cl.on_message
2async def main(message: cl.Message):
3 try:
4 client = await get_temporal_client()
5
6 workflow_id = get_workflow_id(cl.user_session)
7
8 handle = client.get_workflow_handle(
9 workflow_id=workflow_id,
10 )
11
12 thread_id = await handle.query(ConversationThreadWorkflow.get_thread_id)
13
14 async with redis_client.pubsub() as pubsub:
15 # we want to display results as soon as possible.
16 # Or, as soon as they arrive at our temporal activity.
17 # Temporal is not designed to stream results back from a workflow,
18 # it's a workflow engine - it ensures that all our `Actions` are called
19 # successfully and in a proper order.
20 # In order to still stream the results back we introduce a message broker - redis.
21 # So, before sending a message signal to a workflow, we subscribe to redis events
22 # using thread_id as subscription topic.
23 await pubsub.subscribe(thread_id)
24
25 # Once the subscription is established and we are sure that we will receive all events
26 # - send the signal with user prompt
27 await handle.signal(ConversationThreadWorkflow.on_message, message.content)
28
29 # Signal will execute workflow activity (maybe multiple activities)
30 # to add a message to openai thread, to read a response
31 # checking if the tool call is needed...
32 # There will be an activity which calls weather api to get a weather
33 # in user's city, if he asks for it.
34 # All of that is not relevant here. Here, we only care about the fact
35 # that when any of those activities will have information that needs to
36 # be visible on UI as soon as possible, they will push that information to redis.
37
38 cl_message = None
39 while True:
40 message = await pubsub.get_message(ignore_subscribe_messages=True)
41 if message is not None:
42 message_dict = json.loads(message["data"].decode())
43
44 # redis messages format is simple - we have event name under `e`
45 # property and event value (details) under `v` property.
46 # Event names are ones that openai sdk emits.
47
48 if(message_dict["e"] == "on_text_created"):
49 # message was created by openai - create a chainlit message
50 # object so it's displayed on UI (even if it's still has no text)
51 cl_message = await cl.Message(
52 author=assistant.name, content=""
53 ).send()
54 elif(message_dict["e"] == "on_text_delta"):
55 # there are some new tokens in a message, just append them to our
56 # chainlit message object
57 await cl_message.stream_token(message_dict["v"])
58 elif(message_dict["e"] == "on_text_done"):
59 await cl_message.update()
60 await pubsub.unsubscribe(thread_id)
61 break
62
63 except Exception as e:
64 print("An error occurred:", str(e))
65 cl.Message("An error occurred. Please refresh the page and try again.")The code is not very different from regular chainlit application - the only difference is that we send a request to one system (via signal to temporal) and wait for results from another system (via subscription to redis topic).
Before diving onto implementation details of how things work under the hood, let's take a look at high-level architecture diagram:
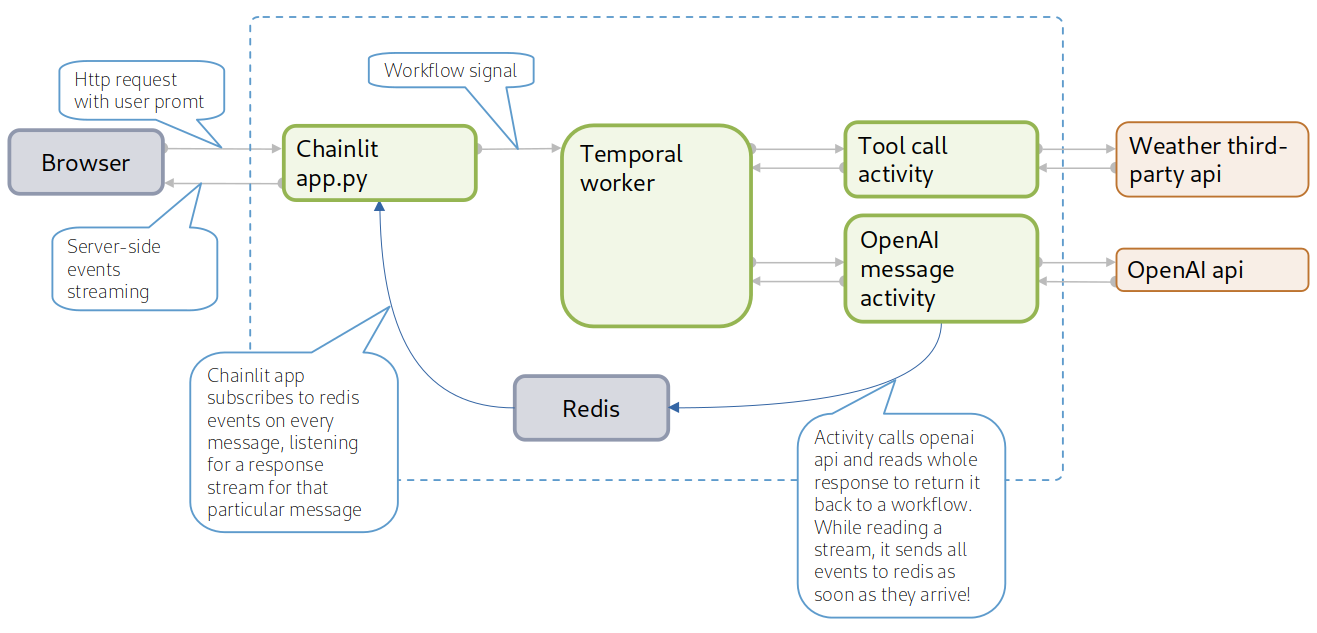
So far, we have covered the left side of the diagram, now let's switch to the right one and talk about the main purpose of adding Temporal to such an application: durable execution of functions. In this proof-of-concept, for the sake of simplicity, only one function is used - a default one suggested by OpenAI user interface when adding a function definition to an assistant on https://platform.openai.com/assistants/
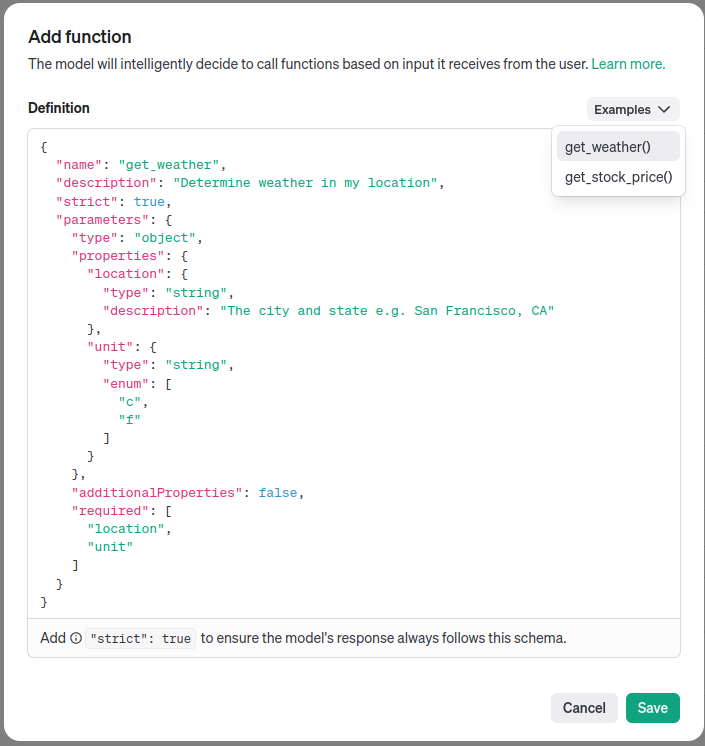
When running the code from repository locally, make sure to create an assistant with get_weather function as in screenshot above and put OpenAI key and assistant id to .env file.
Note that in OpenAI we just define function schema, implementation has to be on the application side. OpenAI API will return special response saying that a tool call is needed, we will have to handle that in our code, call the tool, send tool's response back to OpenAI and wait for the response generated with additional context - tool's output that we submitted.
The implementation of get_weather function is very straightforward and can be found under functions folder.
Now, the workflow's run method:
1@workflow.run
2async def run(
3 self,
4 params: ConversationThreadParams,
5) -> str:
6 self.params = params
7
8 # Before doing anything else, let's make sure we have a thread
9 # to send messages to
10 response = await workflow.execute_activity_method(
11 ConversationThreadActivities.create_thread,
12 schedule_to_close_timeout=timedelta(seconds=5),
13 retry_policy=RetryPolicy(
14 initial_interval= timedelta(seconds=2),
15 backoff_coefficient= 2.0,
16 maximum_interval= None,
17 maximum_attempts= 10,
18 non_retryable_error_types= None
19 )
20 )
21
22 workflow.logger.info("Created thread: " + response)
23
24 self.thread_id = response
25 # Once thread_id is assigned, workflow query will return it,
26 # stopping that while loop in app.py
27
28 # For demonstration purposes we use get_weather function. Well,
29 # weather can be different across the globe, so the second step in a workflow
30 # will be to get a name of a city user is from
31 # For demonstration purposes you can see all possible parameters of RetryPolicy
32 # object
33 self.remote_city = await workflow.execute_activity_method(
34 ConversationThreadActivities.get_city,
35 params.remote_ip_address,
36 schedule_to_close_timeout=timedelta(seconds=5),
37 retry_policy=RetryPolicy(
38 initial_interval= timedelta(seconds=2),
39 backoff_coefficient= 2.0,
40 maximum_interval= None,
41 maximum_attempts= 10,
42 non_retryable_error_types= None
43 )
44 )
45
46 # If you are not familiar with workflow lifetime make sure to check out
47 # courses: https://learn.temporal.io/courses/
48 # This like basically says that workflow will just exist (and is able to receive signals)
49 # until it's thread_closed property is set to True
50 await workflow.wait_condition(lambda: self.thread_closed)
51
52 return "thread closed"
53
54Now, when user sends a message, it will come via signal to a method defined on a workflow:
1@workflow.signal
2async def on_message(self, message: str):
3
4 # This is how openai threads api works - first, we submit the message to a thread
5 await workflow.execute_activity_method(
6 ConversationThreadActivities.add_message_to_thread,
7 ConversationThreadMessage(thread_id=self.thread_id, message=message),
8 schedule_to_close_timeout=timedelta(seconds=5),
9 )
10
11 self.messages.append(ConversationMessage(author="", message=message))
12
13 # and once message is submitted, we can get a response
14 response = await workflow.execute_activity_method(
15 ConversationThreadActivities.get_response,
16 self.thread_id,
17 schedule_to_close_timeout=timedelta(seconds=120),
18 )
19
20 # response may not contain text yet, it's possible that LLM does not
21 # have enough information to generate an answer yet. In that case we will
22 # get `tool_call_needed` property as True and that can happen multiple times
23 while(response.tool_call_needed):
24 tool_arguments = response.tool_arguments
25 tool_arguments.update({
26 "location": self.remote_city # we know where user is located better than LLM
27 }) # because we reverse-geocoded his ip address in
28 # the first step of a workflow
29
30 tool_call_result = await workflow.execute_activity_method(
31 ConversationThreadActivities.function_call,
32 ToolCallRequest(
33 tool_call_id=response.tool_call_id,
34 tool_function_name=response.tool_call_function_name,
35 tool_arguments=response.tool_arguments
36 ),
37 schedule_to_close_timeout=timedelta(seconds=120),
38 )
39
40 # tool_call_result should contain weather's information at this point,
41 # submit it to the LLM!
42 response = await workflow.execute_activity_method(
43 ConversationThreadActivities.submit_tool_call_result,
44 SubmitToolOutputsRequest(
45 thread_id=response.thread_id,
46 run_id=response.run_id,
47 tool_outputs=[tool_call_result]
48 ),
49 schedule_to_close_timeout=timedelta(seconds=120),
50 )
51
52 self.messages.append(ConversationMessage(author="assistant", message=response.message))
53
54Now, the most complicated and interesting part: activities!
As usual, we won't be presenting every line of code, the file is available in the repository.
Activities also look straightforward - we just call OpenAI APIs to get a response stream. The difference in our approach is that EventHandler does not do function calls right away. It accumulates all events into result property so that, when returned from an activity, workflow could know whether a tool call is needed and with what arguments.
1
2@activity.defn
3async def get_response(self, thread_id: str) -> ConversationThreadMessageResponse:
4 assistant = await self.openai_client.beta.assistants.retrieve(
5 assistant_id=self.openai_assistant_id
6 )
7
8 # event handler will ge all events from a response stream as they arrive and accumulate
9 # them in it's properties
10 event_handler = EventHandler(thread_id=thread_id)
11
12 # runs.stream initiates a reader for a results stream
13 # the stream will contain all events happening on openai
14 # like text_created, text_delta, text_done
15 # Basically, for a simple promt 'hi!', the result stream will look like this:
16 #
17 # text_created
18 # text_delta("Hello")
19 # text_delta("! How")
20 # text_delta(" can")
21 # text_delta("I")
22 # text_delta("assist you ")
23 # text_delta("today?")
24 # text_done
25 #
26 # If the LLM will require additional data and will have tools (functions)
27 # configured, the response may not contain text events, but instead it will
28 # have events like tool_call_created etc.
29 #
30 # EventHandler's job is to accumulate all those events and return a final object
31 # with either full response message text or tool name and arguments. While gathering all those
32 # events, EventHandler will also stream them to redis so that UI can pick them up
33 # and display on UI as they arrive
34 async with self.openai_client.beta.threads.runs.stream(
35 thread_id=thread_id,
36 assistant_id=assistant.id,
37 event_handler=event_handler, # all of abovementioned events will be read by EventHandler class
38 ) as stream:
39 # It's a temporal activity, so we need to read the response to the end
40 # and return a result
41 # It's a responsibility of EventHandler to send all events to redis as they arrive
42 # but also to acculumate all events into it's `result` property, so that
43 # temporal workflow knows whether it needs to call a function or no
44 await stream.until_done()
45
46 return event_handler.result
47
48@activity.defn
49async def function_call(self, request: ToolCallRequest) -> ToolCallResult:
50 result = process_function_calls(
51 request.tool_function_name,
52 request.tool_arguments,
53 )
54
55 return ToolCallResult(tool_call_id=request.tool_call_id, output=result)
56
57@activity.defn
58async def submit_tool_call_result(self, request: SubmitToolOutputsRequest) -> ConversationThreadMessageResponse:
59 # This function does everything in the same way as get_response, but also
60 # passes tool results to the LLM
61 # It also uses same EventHandler class because we need to stream the text
62 # to redis
63 event_handler = EventHandler(thread_id=request.thread_id, run_id=request.run_id)
64
65 async with self.openai_client.beta.threads.runs.submit_tool_outputs_stream(
66 thread_id=request.thread_id,
67 run_id=request.run_id,
68 tool_outputs=[{"tool_call_id": x.tool_call_id, "output": x.output} for x in request.tool_outputs],
69 event_handler=event_handler,
70 ) as stream:
71 await stream.until_done()
72
73 return event_handler.result
74Now, the last piece in the architecture - a class that's responsible for gathering all events that are streamed by OpenAI API: EventHandler
1"""
2
3"""
4@dataclass
5class ConversationThreadMessageResponse:
6 thread_id: str
7 run_id: str = ""
8 message: str = ""
9 tool_call_needed: bool = False
10 tool_call_id: str = ""
11 tool_call_function_name: str = ""
12 tool_type: str = ""
13 tool_arguments: Optional[dict] = None
14
15
16"""
17 Event handler class for handling various events in the assistant
18 This class simply passes all events to redis so that results can be displayed on UI immediately,
19 but also it accumulates all data from events into it's `result` object so that, when result is returned from activity, workflow will know whether it needs to call another function.
20"""
21class EventHandler(AsyncAssistantEventHandler):
22 def __init__(self, thread_id: str, run_id: str = "") -> None:
23 super().__init__()
24 self.result: ConversationThreadMessageResponse = ConversationThreadMessageResponse(
25 thread_id=thread_id,
26 run_id=run_id
27 )
28
29 async def on_text_created(self, text) -> None:
30 redis_client.publish(self.result.thread_id, json.dumps({"e": "on_text_created", "v": text.value}))
31 self.result.message = text.value
32
33 async def on_text_delta(self, delta, snapshot):
34 redis_client.publish(self.result.thread_id, json.dumps({"e": "on_text_delta", "v": delta.value}))
35 if not delta.annotations:
36 self.result.message += delta.value
37
38 async def on_text_done(self, text):
39 redis_client.publish(self.result.thread_id, json.dumps({"e": "on_text_done", "v": text.value}))
40 self.result.message = text.value
41
42 """
43 Custom handler for a function call that requires action
44 """
45 async def handle_required_action(self, tool_call):
46 # When the tool call is needed we don't stream anything to redis,
47 # because there is no message to display yet. We can send some event to
48 # display that some tool is being called at the moment but that's out of scope
49 # for this example
50 # here we just record the information about tool that needs to be called - it
51 # will be returned from an activity and workflow will execute another activity
52 # that calls needed function
53 self.result.tool_call_needed = True
54 self.result.tool_type = tool_call.type
55 self.result.run_id = self.current_run.id
56 if tool_call.type == "function":
57 self.result.tool_call_function_name = tool_call.function.name
58 self.result.tool_arguments = json.loads(tool_call.function.arguments)
59
60While Temporal may seem excessive for simple chatbots today, the future of AI assistants makes it clear that its adoption for more complex systems is inevitable. As technology evolves rapidly, what is now limited to simple queries like checking the weather or retrieving a document from a vector store will soon expand into more advanced tasks. For instance, we can easily envision a scenario where an assistant is tasked with scraping all real estate websites in a specific city for 3-bedroom apartments, sorting them by proximity to schools, and making phone calls to arrange viewings. Beyond web scraping, consider the complexities involved in making phone calls and handling all the potential outcomes of scheduling a viewing. Building a resilient system for such tasks would naturally lead to the development of a workflow orchestration engine. But Temporal already exists, and it makes sense to leverage it rather than reinvent the wheel.
